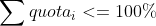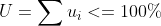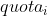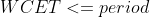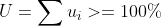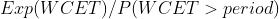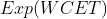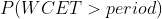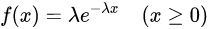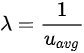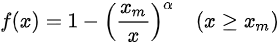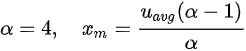让人讨厌的 CPU 限流影响容器运行,有时人们不得不牺牲容器部署密度来避免 CPU 限流出现。我们设计的 CPU Burst 技术既能保证容器运行服务质量,又不降低容器部署密度。CPU Burst 特性已合入 Linux 5.14,Anolis OS 8.2、Alibaba Cloud Linux2、Alibaba Cloud Linux3 也都支持 CPU Burst 特性。
在 K8s 容器调度中,容器的 CPU 资源上限是由 CPU limits 参数指定。设置 CPU 资源上限可以限制个别容器消耗过多的 CPU 运行时间,并确保其他容器拿到足够的 CPU 资源。CPU limits 限制在 Linux 内核中是用 CPU Bandwidth Controller 实现的,它通过 CPU 限流限制 cgroup 的资源消耗。所以当一个容器中的进程使用了超过 CPU limits 的资源的时候,这些进程就会被 CPU 限流,他们使用的 CPU 时间就会受到限制,进程中一些关键的延迟指标就会变差。
面对这种情况,我们应该怎么办呢?一般情况下,我们会结合这个容器日常峰值的 CPU 利用率并乘以一个相对安全的系数来设置这个容器的 CPU limits ,这样我们既可以避免容器因为限流而导致的服务质量变差,同时也可以兼顾 CPU 资源的利用。举个简单的例子,我们有一个容器,他日常峰值的 CPU 使用率在 250% 左右,那么我们就把容器 CPU limits 设置到 400% 来保证容器服务质量,此时容器的 CPU 利用率是 62.5%(250%/400%)。
然而生活真的那么美好吗?显然不是!CPU 限流的出现比预期频繁了很多。怎么办?似乎看上去我们只能继续调大 CPU limits 来解决这个问题。很多时候,当容器的 CPU limits 被放大 5~10 倍的时候,这个容器的服务质量才得到了比较好的保障,相应的这时容器的总 CPU 利用率只有 10%~20%。所以为了应对可能的容器 CPU 使用高峰,容器的部署密度必须大大降低。
历史上人们在 CPU Bandwidth Controller 中修复了一些 BUG 导致的 CPU 限流问题,我们发现当前非预期限流是由于 100ms 级别 CPU 突发使用引起,并且提出 CPU Burst 技术允许一定的 CPU 突发使用,避免平均 CPU 利用率低于限制时的 CPU 限流。在云计算场景中,CPU Burst 技术的价值有:
不提高 CPU 配置的前提下改善 CPU 资源服务质量;
允许资源所有者不牺牲资源服务质量降低 CPU 资源配置,提升 CPU 资源利用率;
降低资源成本(TCO, Total Cost of Ownership)。
你看到的 CPU 利用率不是全部真相
秒级 CPU 利用率不能反映 Bandwidth Controller 工作的 100ms 级别 CPU 使用情况,是导致非预期 CPU 限流出现的原因。
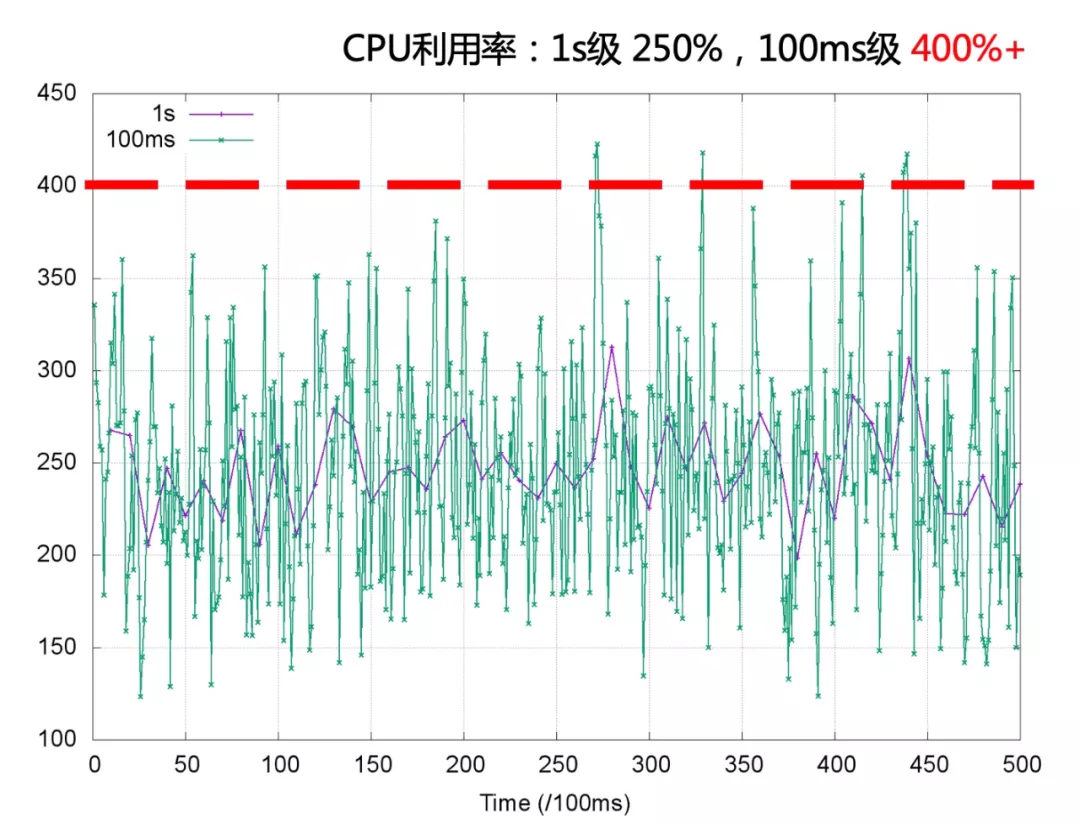
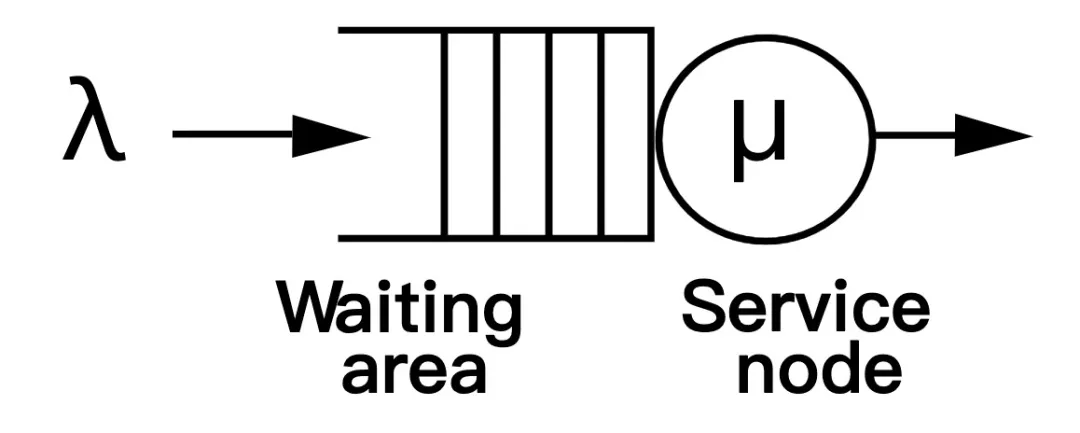
Bandwidth Controller 适用于 CFS 任务,用 period 和 quota 管理 cgroup 的 CPU 时间消耗。若 cgroup 的 period 是 100ms quota 是 50ms,cgroup 的进程每 100ms 周期内最多使用 50ms CPU 时间。当 100ms 周期的 CPU 使用超过 50ms 时进程会被限流,cgroup 的 CPU 使用被限制到 50%。 CPU 利用率是一段时间内 CPU 使用的平均,以较粗的粒度统计 CPU 的使用需求,CPU 利用率趋向稳定;当观察的粒度变细,CPU 使用的突发特征更明显。以 1s 粒度和 100ms 粒度同时观测容器负载运行,当观测粒度是 1s 时 CPU 利用率的秒级平均在 250% 左右,而在 Bandwidth Controller 工作的 100ms 级别观测 CPU 利用率的峰值已经突破 400% 。
编辑
根据秒级观察到的 CPU 利用率 250% 设置容器 quota 和 period 分别为 400ms 和 100ms ,容器进程的细粒度突发被 Bandwidth Controller 限流,容器进程的 CPU 使用受到影响。
如何改善
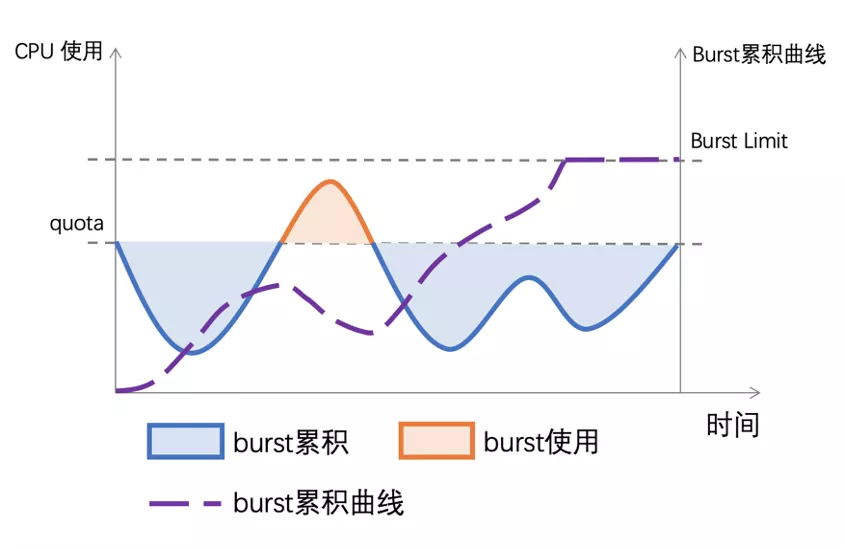
我们用 CPU Burst 技术来满足这种细粒度 CPU 突发需求,在传统的 CPU Bandwidth Controller quota 和 period 基础上引入 burst 的概念。当容器的 CPU 使用低于 quota 时,可用于突发的 burst 资源累积下来;当容器的 CPU 使用超过 quota,允许使用累积的 burst 资源。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。
使用 CPU Bandwidth Controller 可以避免某些进程消耗过多 CPU 时间,并确保所有需要 CPU 的进程都拿到足够的 CPU 时间。之所以有这样好的稳定性保证,是因为当 Bandwidth Controller 设置满足下述情况时,
编辑
有如下的调度稳定性约束:
编辑
其中,
编辑
是第 i 个 cgroup 的 quota,是一个 period 内该 cgroup 的 CPU 需求。Bandwidth Controller 对每个周期分别做 CPU 时间统计,调度稳定性约束保证在一个 period 内提交的全部任务都能在该周期内处理完;对每个 CPU cgroup 而言,这意味着任何时候提交的任务都能在一个 period 内执行完,即任务实时性约束:
编辑
调度器稳定性被打破,在每个 period 都有任务积攒下来,新提交的作业执行时间不断增加。
使用 CPU Burst 的影响
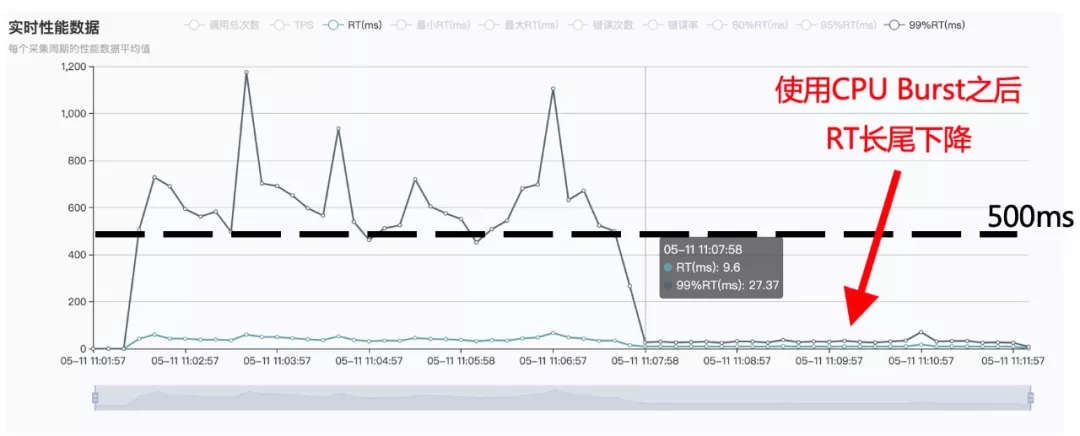
出于改善服务质量的需要,我们使用 CPU Burst 允许突发的 CPU 使用之后,对调度器的稳定性产生什么影响?答案是当多个 cgroup 同时突发使用 CPU,调度器稳定性约束和任务实时性保证有可能被打破。这时候两个约束得到保证的概率是关键,如果两个约束得到保证的概率很高,对大多数周期来任务实时性都得到保证,可以放心大胆使用 CPU Burst;如果任务实时性得到保证的概率很低,这时候要改善服务质量不能直接使用 CPU Burst,应该先降低部署密度提高 CPU 资源配置。
于是下一个关心的问题是,怎么计算特定场景下两个约束被打破的概率。
评估影响大小
定量计算可以定义成经典的排队论问题,并且用蒙特卡洛模拟方法求解。定量计算的结果表明,判断当前场景是否可以使用 CPU Burst 的主要影响因素是平均 CPU 利用率和 cgroup 数目。CPU 利用率越低,或者 cgroup 数目越多,两个约束越不容易被打破可以放心使用 CPU Burst。反之如果 CPU 利用率很高或者 cgroup 数目较少,要消除 CPU 限流对进程执行的影响,应该降低部署提高配置再使用 CPU Burst。
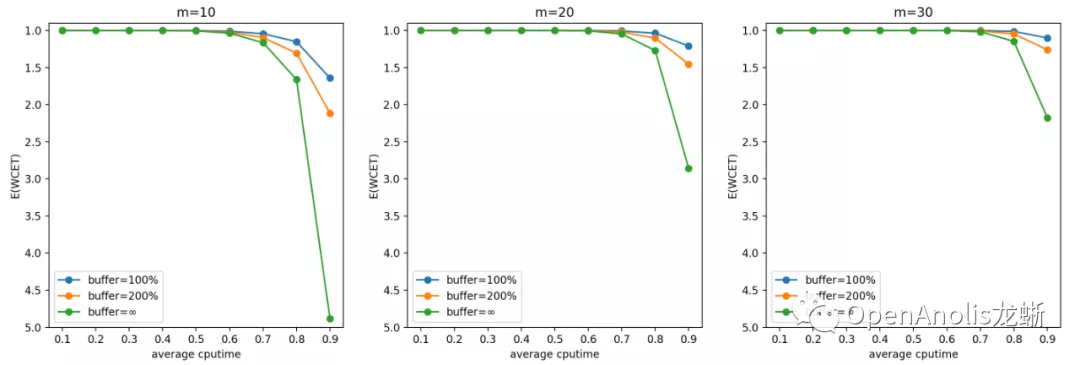
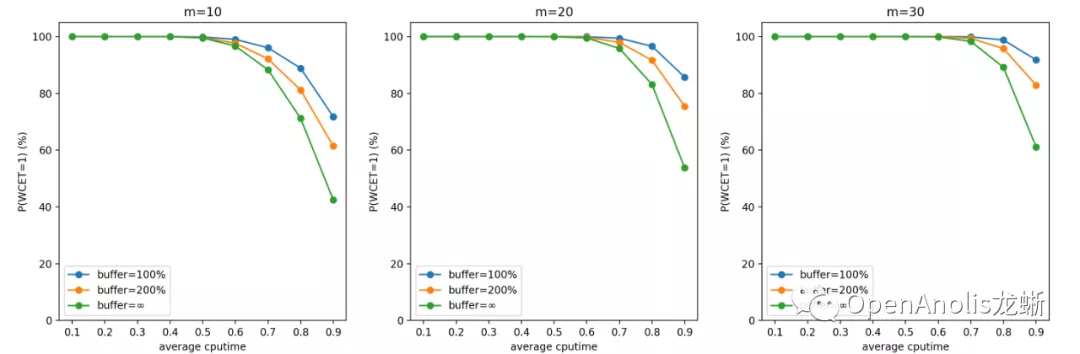
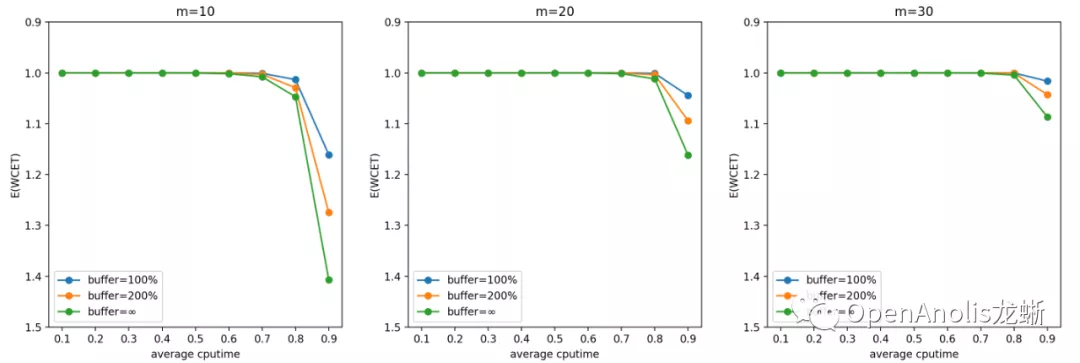
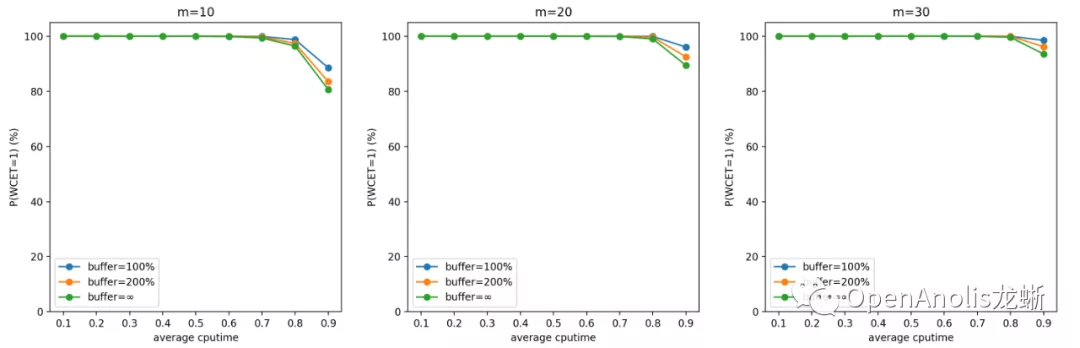
问题定义是:一共有 m 个 cgroup,每个 cgroup 的 quota 限制为 1/m,每个 cgroup 在每个周期产生的计算需求(CPU 利用率)服从某个具体分布,这些分布是相互独立的。假设任务在每个周期的开始到达,如果该周期内的 CPU 需求超过 100%,当前周期任务 WCET 超过 1 个 period,超过的部分累积下来和下个周期新产生的 CPU 需求一起在下个需求处理。输入是 cgroup 的数目 m 和每个 CPU 需求满足的具体分布,输出是每个周期结束 WCET > period 的概率和 WCET 期望。
以输入的 CPU 需求为帕累托分布、m=10/20/30 的结果为例进行说明。选择帕累托分布进行说明的原因是它产生比较多的长尾 CPU 突发使用,容易产生较大影响。表格中数据项的格式为
编辑
根据模拟结果,开启 CPU Burst 功能对该业务场景下的容器几乎没有负面影响,小 A 可以放心使用啦。 想要进一步了解该工具的用法,或是出于对理论的兴趣去改变分布查看模拟结果,都可以访问上面的仓库链接找到答案~ 关于作者
常怀鑫(一斋),阿里云内核组工程师,擅长 CPU 调度领域。
丁天琛(鹰羽),2021 年加入阿里云内核组,目前在调度领域等方面学习研究。



 发表于 2022-12-25 14:35:23
发表于 2022-12-25 14:35:23