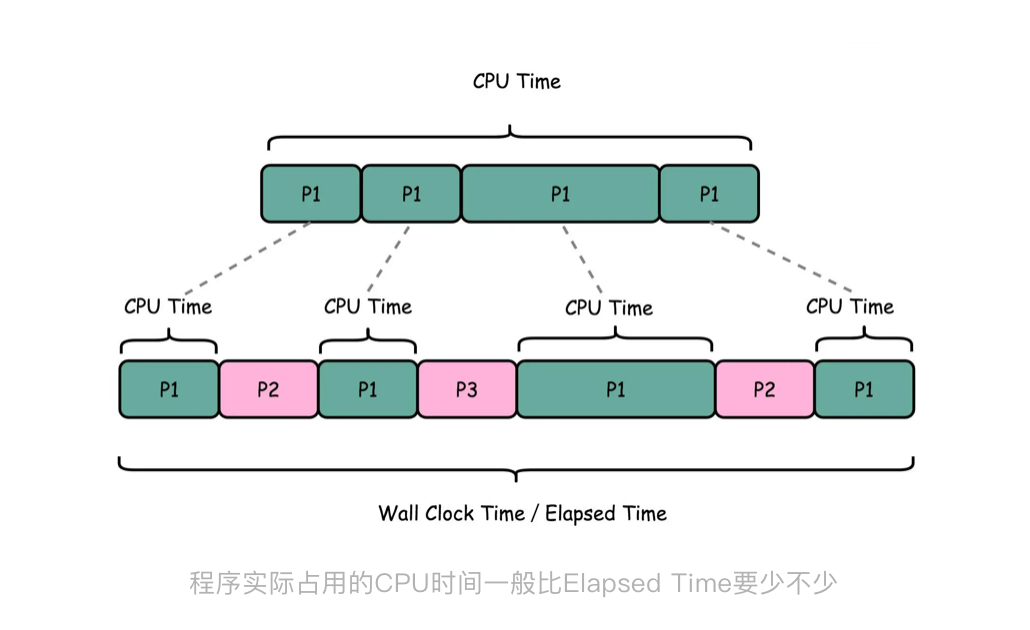
为什么会不准呢?这里面有好几个原因。首先,我们统计时间是用类似于“掐秒表”一样,记录程序运行结束的时间减去程序开始运行的时间。这个时间也叫 Wall Clock Time 或者 Elapsed Time,就是在运行程序期间,挂在墙上的钟走掉的时间。
但是,计算机可能同时运行着好多个程序,CPU 实际上不停地在各个程序之间进行切换。在这些走掉的时间里面,很可能 CPU 切换去运行别的程序了。而且,有些程序在运行的时候,可能要从网络、硬盘去读取数据,要等网络和硬盘把数据读出来,给到内存和 CPU。所以说,要想准确统计某个程序运行时间,进而去比较两个程序的实际性能,我们得把这些时间给刨除掉。
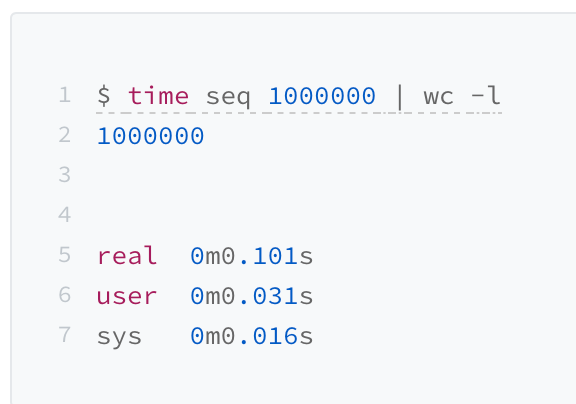
那这件事怎么实现呢?Linux 下有一个叫 time 的命令,可以帮我们统计出来,同样的 Wall Clock Time 下,程序实际在 CPU 上到底花了多少时间。
我们简单运行一下 time 命令。它会返回三个值,第一个是 real time,也就是我们说的 Wall Clock Time,也就是运行程序整个过程中流逝掉的时间;第二个是 user time,也就是 CPU 在运行你的程序,在用户态运行指令的时间;第三个是 sys time,是 CPU 在运行你的程序,在操作系统内核里运行指令的时间。而程序实际花费的 CPU 执行时间(CPU Time),就是 user time 加上 sys time。
在我给的这个例子里,你可以看到,实际上程序用了 0.101s,但是 CPU time 只有 0.031+0.016 = 0.047s。运行程序的时间里,只有不到一半是实际花在这个程序上的。
备注:你最好在云平台上,找一台 1 CPU 的机器来跑这个命令,在多 CPU 的机器上,seq 和 wc 两个命令可能分配到不同的 CPU 上,我们拿到的 user time 和 sys time 是两个 CPU 上花费的时间之和,可能会导致 real time 可能会小于 user time+sys time。
其次,即使我们已经拿到了 CPU 时间,我们也不一定可以直接“比较”出两个程序的性能差异。即使在同一台计算机上,CPU 可能满载运行也可能降频运行,降频运行的时候自然花的时间会多一些。
除了 CPU 之外,时间这个性能指标还会受到主板、内存这些其他相关硬件的影响。所以,我们需要对“时间”这个我们可以感知的指标进行拆解,把程序的 CPU 执行时间变成 CPU 时钟周期数(CPU Cycles)和 时钟周期时间(Clock Cycle)的乘积。
如果想要更准确一点描述,这个 2.8GHz 就代表,我们 CPU 的一个“钟表”能够识别出来的最小的时间间隔。就像我们挂在墙上的挂钟,都是“滴答滴答”一秒一秒地走,所以通过墙上的挂钟能够识别出来的最小时间单位就是秒。
而在 CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(Oscillator Crystal)的东西,简称为晶振。我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。
在我这个 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。我们的 CPU,是按照这个“时钟”提示的时间来进行自己的操作。主频越高,意味着这个表走得越快,我们的 CPU 也就“被逼”着走得越快。
如果你自己组装过台式机的话,可能听说过“超频”这个概念,这说的其实就相当于把买回来的 CPU 内部的钟给调快了,于是 CPU 的计算跟着这个时钟的节奏,也就自然变快了。当然这个快不是没有代价的,CPU 跑得越快,散热的压力也就越大。就和人一样,超过生理极限,CPU 就会崩溃了。
我们现在回到上面程序 CPU 执行时间的公式。
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
最简单的提升性能方案,自然缩短时钟周期时间,也就是提升主频。换句话说,就是换一块好一点的 CPU。不过,这个是我们这些软件工程师控制不了的事情,所以我们就把目光挪到了乘法的另一个因子——CPU 时钟周期数上。如果能够减少程序需要的 CPU 时钟周期数量,一样能够提升程序性能。
对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)”。不同的指令需要的 Cycles 是不同的,加法和乘法都对应着一条 CPU 指令,但是乘法需要的 Cycles 就比加法要多,自然也就慢。在这样拆分了之后,我们的程序的 CPU 执行时间就可以变成这样三个部分的乘积。



 发表于 2022-12-11 18:42:12
发表于 2022-12-11 18:42:12