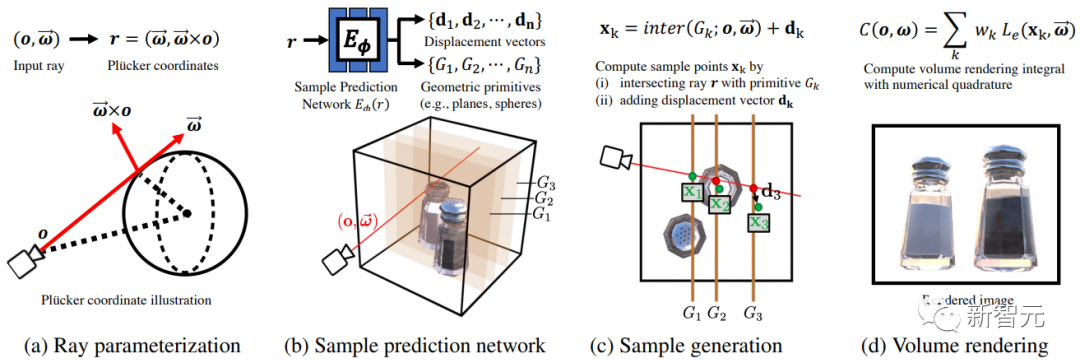
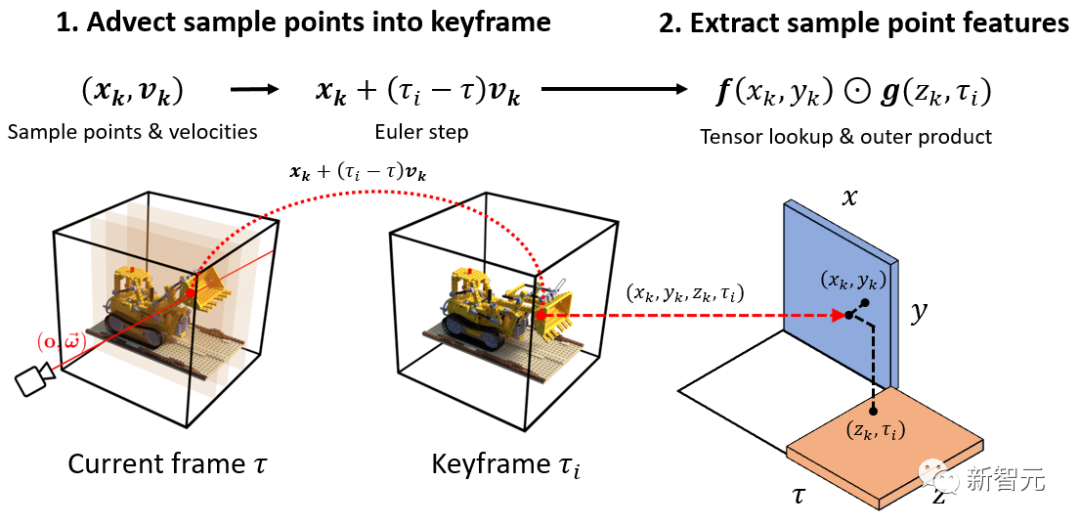
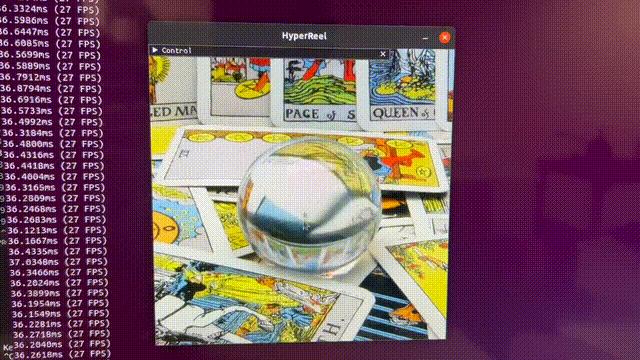
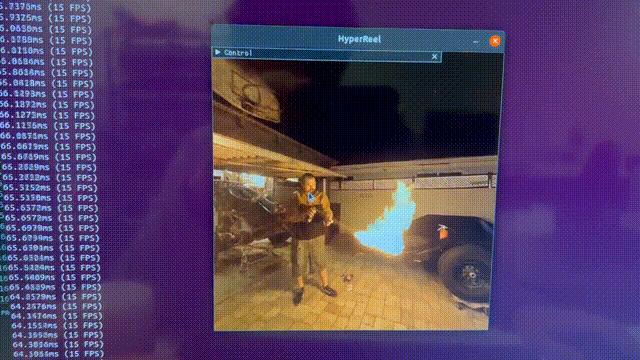
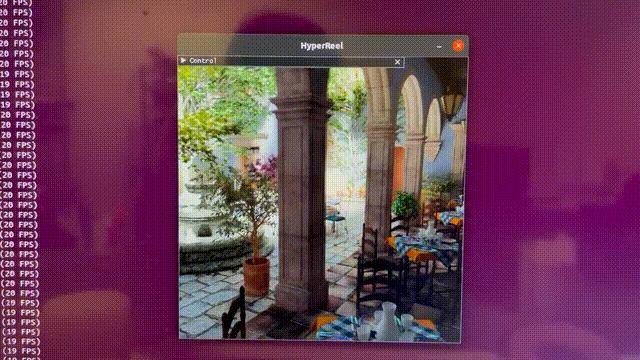
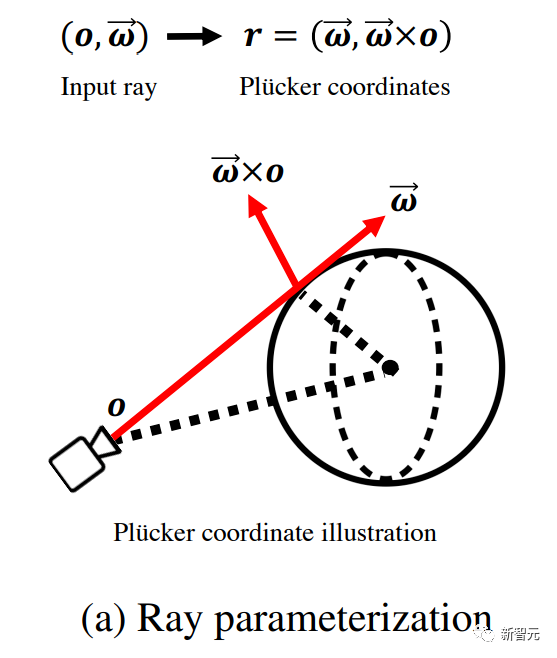
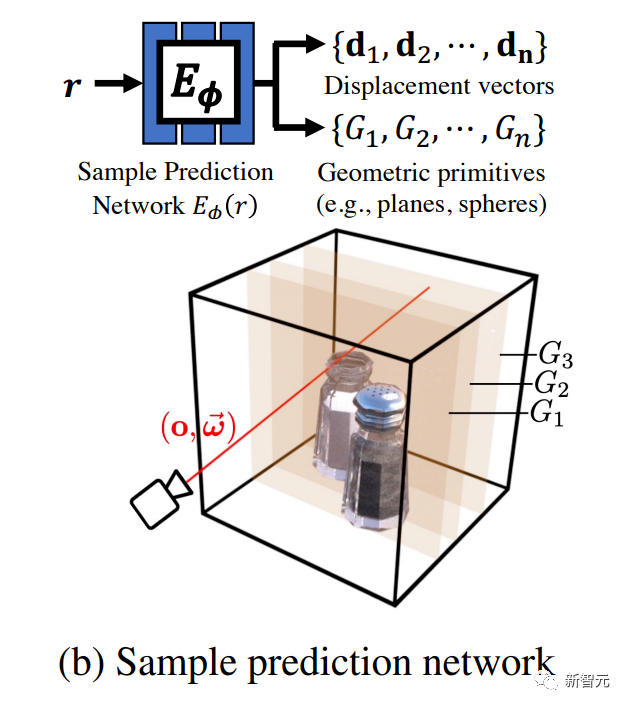
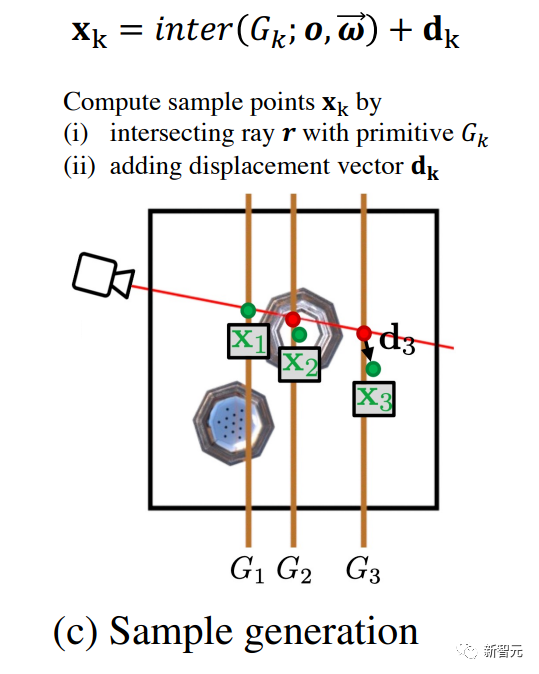
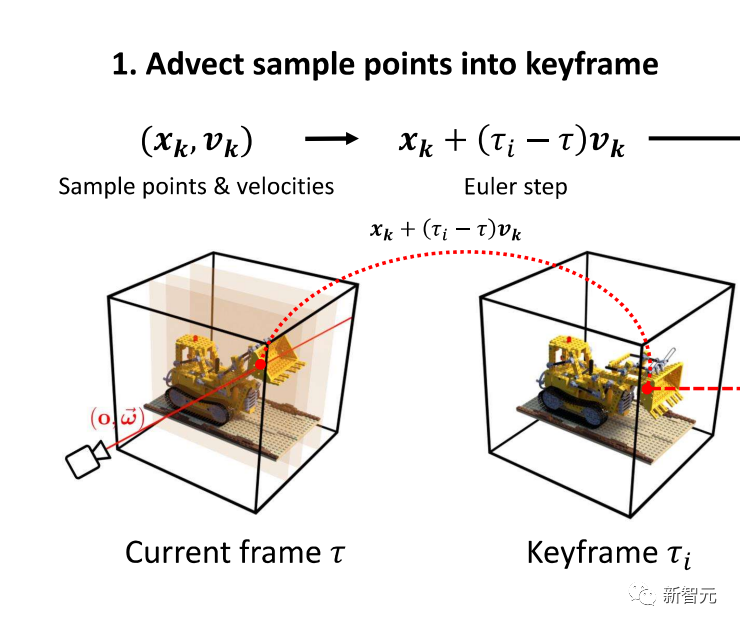
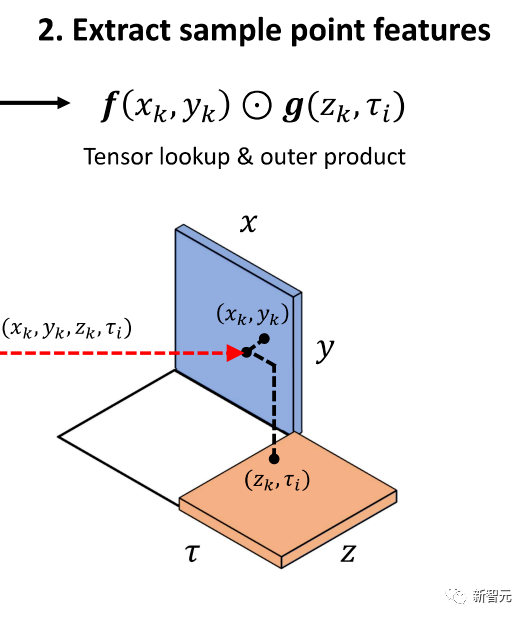
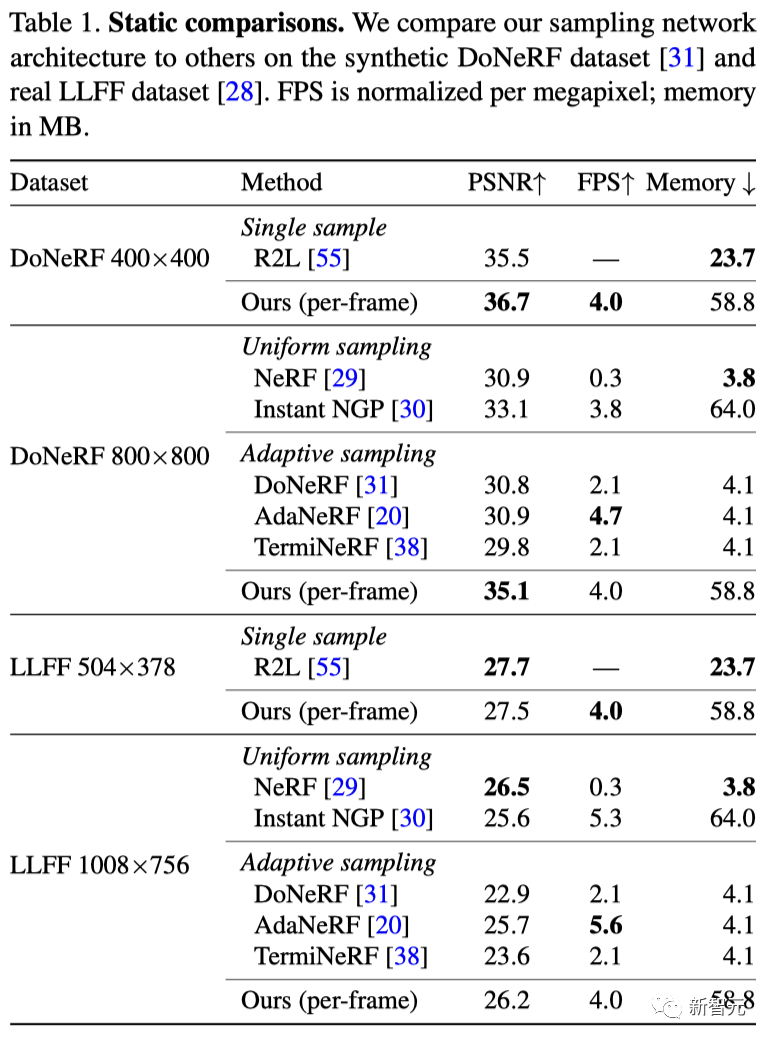
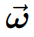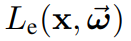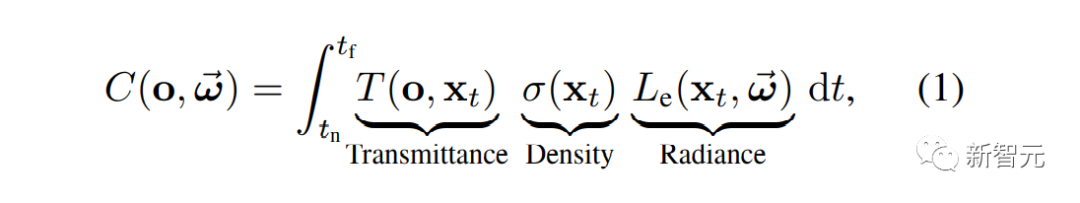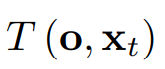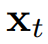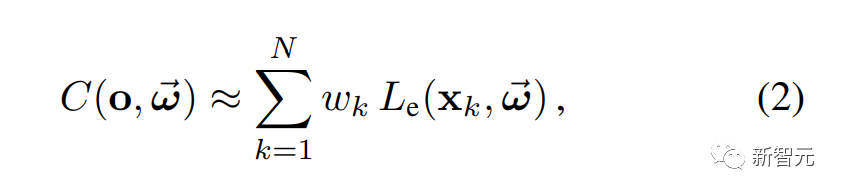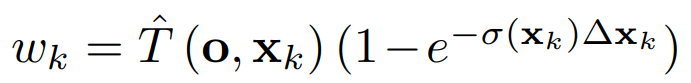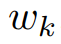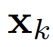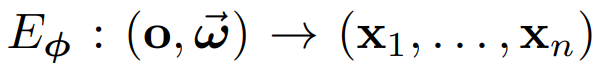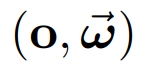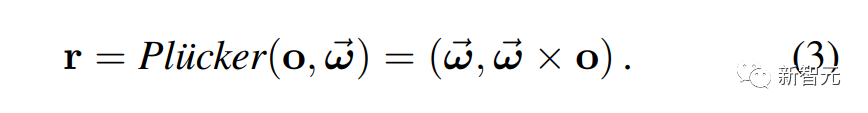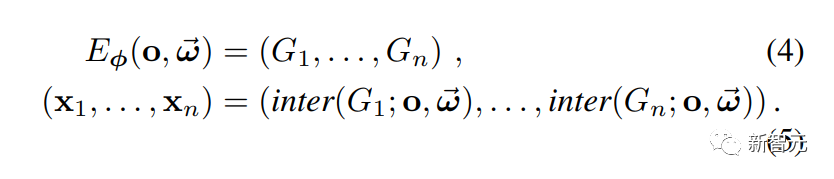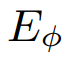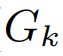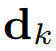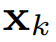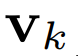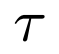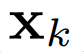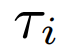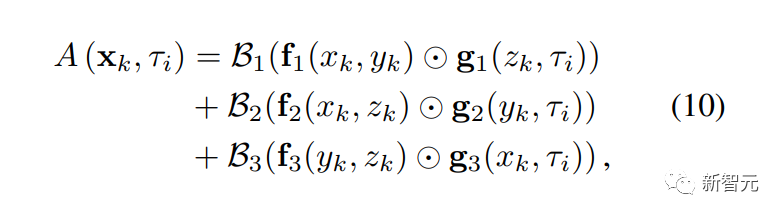体积场景表征(volumetric scene representation)能够为静态场景提供逼真的视图合成,并构成了现有6-DoF视频技术的基础。
然而,驱动这些表征的体积渲染程序,需要在质量、渲染速度和内存效率方面,进行仔细的权衡。
现有的方法有一个弊端——不能同时实现实时性能、小内存占用和高质量渲染,而在极具挑战性的真实场景中,这些都是极为重要的。
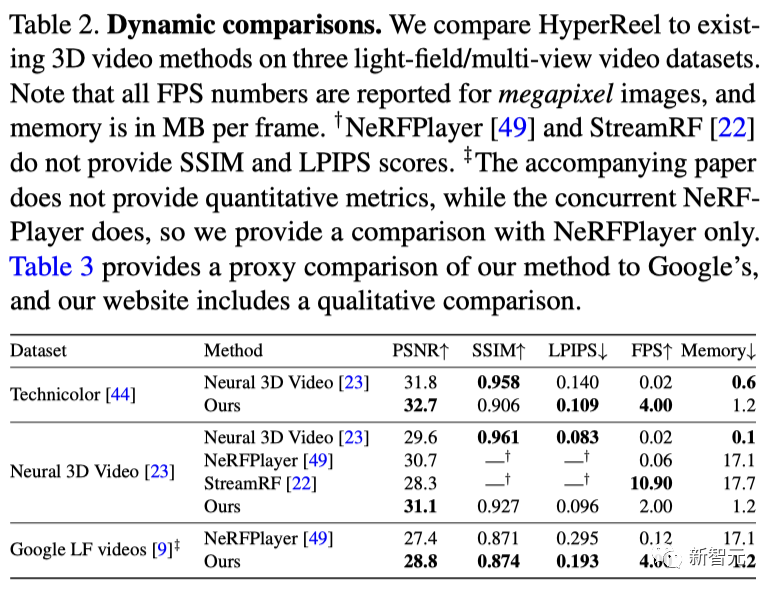
Technicolor光场数据集包含了由时间同步的4×4摄像机装置拍摄的各种室内环境的视频,其中每个视频流中的每张图片都是2048×1088像素。
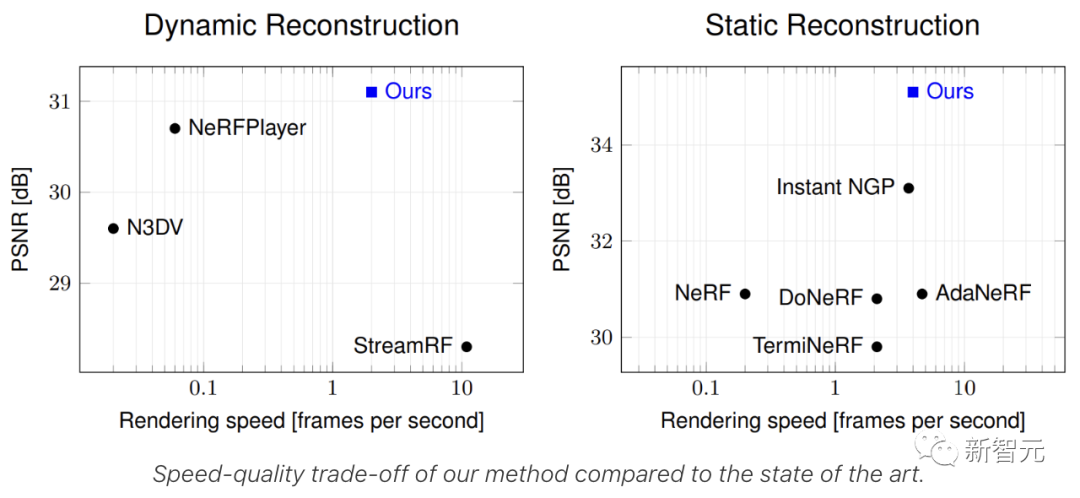
研究人员将HyperReel和Neural 3D Video在全图像分辨率下对这个数据集的五个序列(Birthday, Fabien, Painter, Theater, Trains)进行比较,每个序列有50帧长。如表2所示,HyperReel的质量超过了Neural 3D Video,同时每个序列的训练时间仅为1.5个小时(而不是Neural 3D的1000多个小时),并且渲染速度更快。
Neural 3D Video数据集
Neural 3D Video数据集包含6个室内多视图视频序列,由20台摄像机以2704×2028像素的分辨率拍摄。
如表2所示,HyperReel在这个数据集上的表现超过了所有的基线方法,包括NeRFPlayer和StreamRF等最新工作。特别是,HyperReel在数量上超过了NeRFPlayer,渲染速度是其40倍左右;在质量上超过了StreamRF,尽管其采用Plenoxels为骨干的方法(使用定制的CUDA内核来加快推理速度)渲染速度更快。此外,HyperReel平均每帧消耗的内存比StreamRF和NeRFPlayer都要少得多。



 发表于 2023-1-14 12:22:18
发表于 2023-1-14 12:22:18